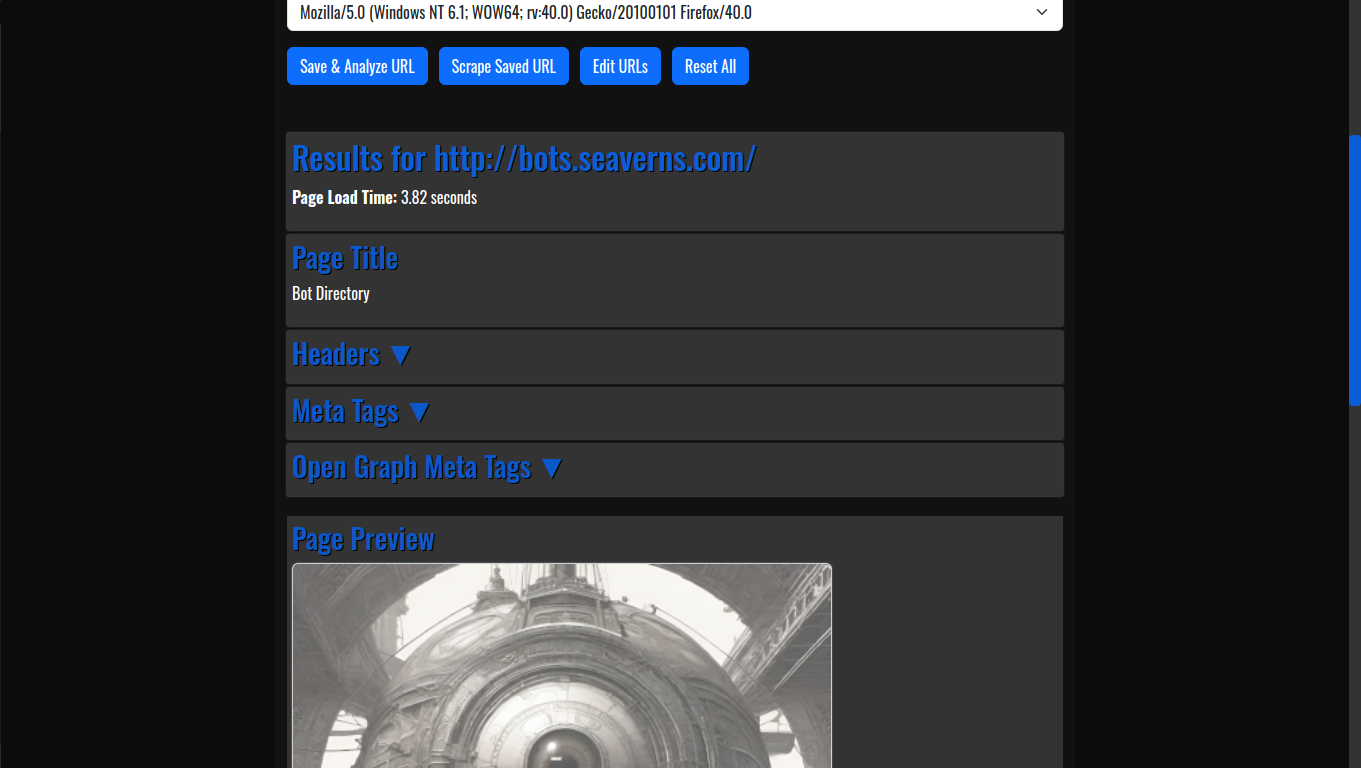
WonderMule Stealth Scraper
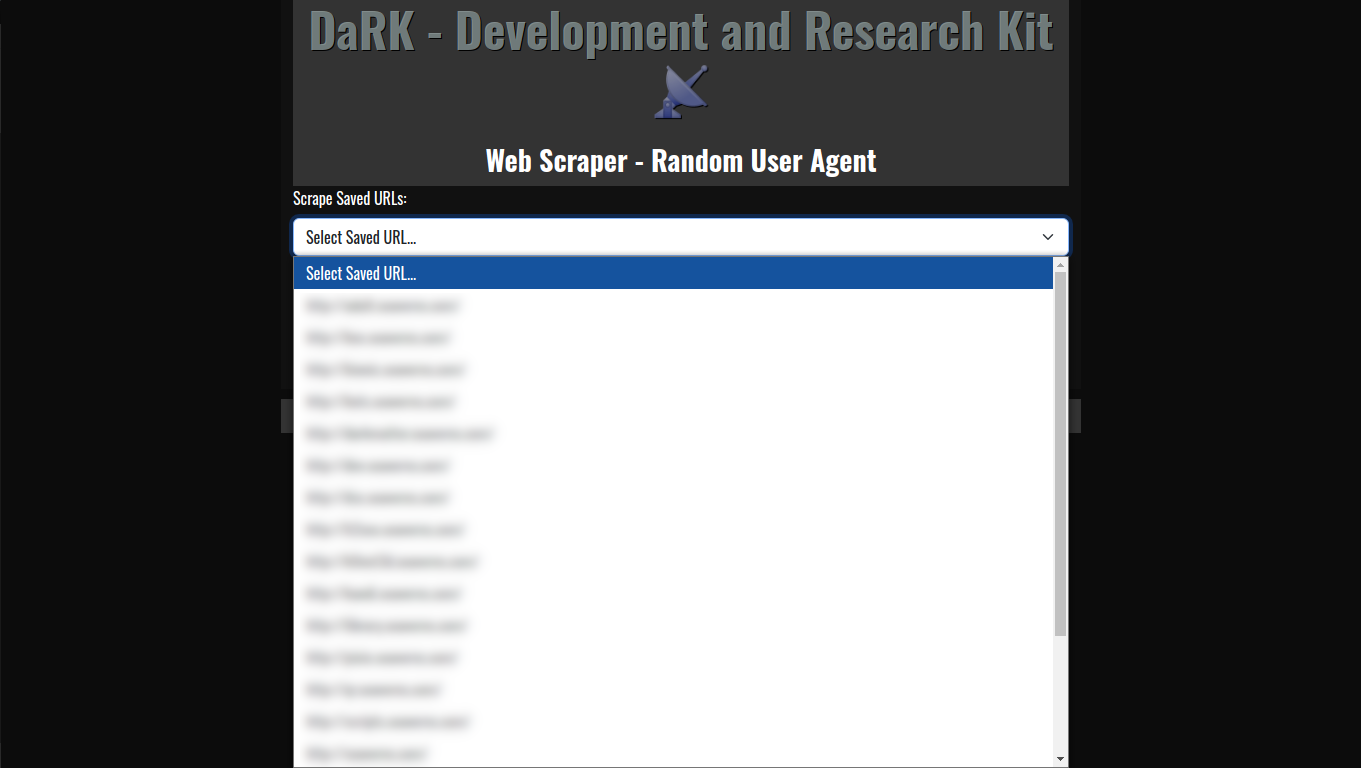
WonderMule Stealth Scraper:
A Powerful and Efficient Web Scraping Tool.
WonderMule Stealth Scraper is a cutting-edge, highly efficient, and stealthy web scraping application designed to extract data from websites without triggering security measures or firewall blocks. It serves as an invaluable tool for security professionals, researchers, and data analysts alike. Whether you’re working in the realms of ethical hacking, threat intelligence, or simply need to scrape and mine data from the web without leaving a trace, WonderMule provides a robust solution.

WonderMule Stealth Scraper
Key Features
- Super Fast and Efficient
WonderMule is built with speed and efficiency in mind. Utilizing Python’shttpxlibrary, an asynchronous HTTP client, the tool can handle multiple requests simultaneously. This allows for quick extraction of large datasets from websites.httpxenables non-blocking I/O operations, meaning that it doesn’t have to wait for responses before continuing to the next request, resulting in a much faster scraping process compared to synchronous scraping tools. - Stealthy Firewall Evasion
One of the standout features of WonderMule is its ability to bypass firewalls and evade detection. Websites and web servers often employ anti-scraping measures such as IP blocking and rate limiting to protect their data. WonderMule has built-in functionality that alters theUser-Agentand mimics legitimate traffic, making it harder for servers to distinguish between human users and the scraper.
This makes it particularly useful in environments where security measures are stringent.
WonderMule is even often missed entirely, as discovered testing against several well-known firewalls.
This feature makes it an invaluable and in some instances, even unethical or illegal to use.
No Public Download Will Be Made Available. - Torsocks Compatibility
WonderMule comes pre-configured for seamless integration with torsocks, allowing users to route their traffic through the Tor network for anonymity and additional privacy. This feature is useful for those who need to maintain a low profile while scraping websites. By leveraging the Tor network, users can obfuscate their IP address and further reduce the risk of being detected by security systems. - CSV Output for Easy Data Import
The application generates output in CSV format, which is widely used for data importation and manipulation. Data scraped from websites is neatly organized into columns such as titles, links, and timestamps. This makes it easy to import the data into other technologies and platforms for further processing, such as databases, Excel sheets, or analytical tools. The structured output ensures that the scraped data is immediately usable for various applications. - Lightweight and Portable
Despite its rich feature set, WonderMule remains lightweight, with the full set of libraries and dependencies bundled into a 12.3MB standalone executable. This small footprint makes it highly portable and easy to run on different systems without requiring complex installation processes. Users can run the application on any compatible system, making it an ideal choice for quick deployments in various environments.
WonderMule Stealth Scraper:
Functions and How It Works
At its core, WonderMule utilizes Python’s httpx library to send asynchronous HTTP requests to target websites. The process begins when a URL is provided to the scraper. The scraper then makes an HTTP GET request to the server using a custom user-agent header (configured to avoid detection). The response is parsed using BeautifulSoup to extract relevant data, such as article titles, links, and timestamps. Once the data is extracted, it is written to a CSV file for later use.
The integration of asyncio enables the scraper to handle multiple requests concurrently, resulting in faster performance and better scalability. The data is collected in real-time, and the CSV output is structured in a way that it can be easily integrated into databases, spreadsheets, or other analytical tools.
A Versatile Tool for Security Experts and Data Miners
WonderMule’s versatility makes it valuable for a broad spectrum of users. Black hat hackers may use it to gather intelligence from various websites while staying undetected. White hat professionals and penetration testers can leverage its stealth features to evaluate the security posture of websites and detect vulnerabilities such as weak firewall protections or improper rate limiting. Moreover, data analysts and researchers can use WonderMule to perform data mining on websites for trend analysis, market research, or competitive intelligence.
Whether you’re conducting a security audit, gathering publicly available data for research, or looking to extract large sets of information without triggering detection systems, WonderMule Stealth Scraper is the perfect tool for the job. With its speed, stealth, and portability, it offers a unique blend of functionality and ease of use that is difficult to match.
WonderMule Stealth Scraper
WonderMule Stealth Scraper provides a powerful solution for anyone needing to extract data from the web quickly and discreetly. Whether you are working on a security project, performing ethical hacking tasks, or conducting large-scale data mining, WonderMule’s ability to bypass firewalls, its compatibility with Tor for anonymous scraping, and its lightweight nature make it a top choice for both security professionals and data analysts.